プログラマが知るべき97のことに寄稿していません
12月18日にオライリーから発売されるプログラマが知るべき97のことに寄稿していません。

- 作者: 和田卓人,Kevlin Henney,夏目大
- 出版社/メーカー: オライリージャパン
- 発売日: 2010/12/18
- メディア: 単行本(ソフトカバー)
- 購入: 58人 クリック: 2,107回
- この商品を含むブログ (350件) を見る
最近のネットデマについて
- ソースをろくに確認せずに取り敢えず拡散する
- 自分の発言の責任が希薄になるように計算されたテンプレート
- 詳細はリンク先で
- 真偽不明ですが取り敢えず拡散
- 自己責任で
- 元情報が訂正されても、拡散した誤情報は消えない
「あなたのGmailをすべて盗まれる」問題
- http://b.hatena.ne.jp/entry/jp.techcrunch.com/archives/20101120whoa-google-thats-a-pretty-big-security-hole/
- http://topsy.com/jp.techcrunch.com/archives/20101120whoa-google-thats-a-pretty-big-security-hole/
- http://disqus.com/guest/84d6bff45c2112e083c425e39f954f5e/
- http://twitter.com/yomoyomo/status/6692549821464576
「メールアドレス」を「メール」と誤解したのはともかく「すべて」はどっから出てきたんだ「すべて」は。面白おかしく大げさにかきたてようとしてるからこういうことになるんじゃないのか?この情報を拡散したバカどもは「(編集部からの修正とお詫び)記事の見出しに「Gmailをすべて盗まれる」とありますが、正しくはGoogleにログインしている(Gmailの)メールアドレスを盗まれるが正しい表現でした。修正してお詫びいたします。(2010年11月27日)」という文言を読みましたか?
mixiアプリで個人情報漏洩する騒動
- 12/06日現在 twitterでの言及 約6500件 http://topsy.com/mixi.jp/manage_acl.pl
- 12/06日現在 mixi内 1276件 http://mixi.jp/search_diary.pl?keyword=http%3A%2F%2Fmixi.jp%2Fmanage_acl.pl&x=0&y=0&submit=search&type=dia
メールアドレスからmixiアカウントを検索できる機能が問題になったのは記憶に新しいが、
- メールアドレスを知っているが、その持ち主を知らない
- メールアドレスと、その持ち主を知っているが、mixiアカウントを知らない
というケース、つまり文字列は知っているが関係性を知らない、というケースで「非公開の情報」がデフォルトで公開になった。だから問題が起きた。
それに対してこれ http://mixi.jp/manage_acl.pl は 元々「(mixi内で全体)公開されている情報」をAPI経由で取得できるようにするか、という設定だ。そのユーザーのマイミク一覧も、マイミク一覧から辿って取得できる全体公開されているプロフィールも、mixiアカウントを持っていれば誰でもアクセスできる情報だ。(実際に大量に取得しようとしたら足あと付けまくってアクセス制限を受けるだろうが)
他のサービスと比較してみよう
- twitterはprotected(許可した人にのみ公開)にしていても(あなたのフォロワーが許可すれば)OAuthで第三者から読まれるし、それを拒否することは出来ない。
- twitterのDM(特定相手にのみ届くメッセージ)であっても(送信先の相手が許可すれば)OAuthで第三者から読まれるし、それを拒否することは出来ない。
- あなたが送ったメールを第三者に見られたくないと思っていてもGmailは(あなたの友人が許可すれば)OAuthでアクセスすることが出来る http://code.google.com/intl/ja/apis/gmail/oauth/
- あなたがメールアドレスを第三者に知られたくないと思っていても(あなたの友人が許可すれば)Google Contacts APIを通じて取得することが出来る http://code.google.com/intl/ja/apis/contacts/
mixiは「あなたの友人が許可しても」全体公開ではない情報にはアクセス出来ない、という世界的に成功しているグローバルなサービスと比較して見ると極めて消極的で限定的なアクセスしか許可していない(参考: http://developer.mixi.co.jp/appli/spec/pc/permission_model )
このデフォルト設定を本気で不適切だと思っている人は、今すぐTwitterとかGoogleとか使うのやめた方がいいし、gmail使ってる人にメール送るのも止めた方がいいし、アドレス帳に入らないように関わるのも避けたほうがいい。Twitter上で言及している人間は滑稽だ。
その設定は危険だから今すぐ変えましょう、などと言われてホイホイ変える人間は逆の行動も容易に起こすので、例えば
- 安全のためと言われて偽セキュリティソフトをインストールしたり
- パスワードの変更したほうが良いと促されて偽サイトにパスワードを入力したり
- PCを高速化するコマンドだと言われてHDDをフォーマットするコマンドを入力したり
- 体に良いと言って水銀をゴクゴク飲んだり、お節介で井戸水に水銀を入れたりする
つまり人間が大量に死ぬ、暴動が起こり核戦争で人類が滅びる。
ネットデマを防ぐために今、我々が出来ること
そのような人間を忘年会に誘うのを止めろ!
図書館クロール補足
なんか技術的におかしなことを言っている人がいたら追記していくかも知れません。
クロール頻度が妥当かどうかの話
ウェブサーバーはマルチスレッド、マルチプロセスなどで複数のリクエストを同時に処理できるようになっているのが一般的であるため「前回のリクエストが完了してから、次のリクエストを投げる」実装になっている限りは「サーバーの性能を100%使いきって他の利用者が利用できない状態」になることは、通常起きません。
例外的なケースもあります。
- ウェブサーバーがリクエスト完了後に何らかの処理を行うような実装になっていて、リクエストのペースによっては処理が溜まっていって追いつかなくなる。
- ロードバランサ、リバースプロキシを使ったフロントエンド/バックエンドの構成になっているサーバーで、フロントエンドがタイムアウトと判断して早々にエラーを返したが実際はバックエンドで処理が続いている。
例えば1秒で処理が終わらないページ(例:LIKE検索)に対して、レスポンスの受信を待たずに1秒に1回のペースでリクエストを投げ続けたら、サービス停止を引き起こせるでしょう。ですが、並列してリクエストを投げていないのに「お前のリクエストが原因で他の利用者が利用できない状態になった」という主旨のことを言われたのであれば、それは通常言いがかりです。他の利用者のリクエストと合わせて過負荷状態になっている(一人の責任にされるべきものではない)か、アプリケーションのバグが原因の事故であると考えるのが自然です。
「サーバーリソースが限られているので遠慮してくれ」というのは、別段おかしなことではありません。が、サービス停止の責任を追求されるのは異常なことです。
1秒1回のペースが妥当かどうかとか、どの程度のウェイトを入れるべきなのかという話は、クロール対象のサービスの規模や、静的ページか動的ページかなどによっても変わるでしょう。もし書いたプログラムを配布する場合は、複数の利用者によってリクエストが同時に投げられることになるので、慎重さが要求されるでしょう。
開発中で自分の手元でしか動いていない相手先のサーバーに並列アクセスしないクローラが原因でサービスが落ちて他の利用者が迷惑しているといって責任を追求されるというのは、技術的におかしいことを言われているのです。それは予見できない事故です。並列アクセスしてないのにサーバーが落ちるのであれば、それはサーバー側のバグが原因である可能性が高い(実際そういう考察をしている人が何人かいますね)。
という程度のことを警察が判断できるようになると良いですね。
適切なエラーハンドリングについて
http://librahack.jp/okazaki-library-case/conclusion.html
相手サーバからのレスポンスHTTP500を細かくハンドリングせず単にスキップだけしていた
これ特におかしなことではないです。おかしいと思っている人は、今回のケースでエラー処理を怠ることによって相手先のサーバーに何か損害を与えうると考えていますか?むしろ不適切なエラー処理(際限なくリトライなど)をしたほうが損害を与える可能性が高いです。
一部の特に行儀の良いクローラであれば500エラーが返ってきた際に同一のサーバーに対するクロール頻度を下げるなどするでしょう。一度エラーが起きたURLに対してリクエスト内容を修正せずに、間を置かずにリクエストを繰り返すのは、同様のエラーが返ってくる可能性が高いので避けるべきです。しかしスキップして次のURLを取得するのであれば、別のリクエストですから正常に返ってくる可能性があります。
連続して500エラーを返していた場合でも、それが自分のリクエストによってサービスダウンを招いているという(並列アクセスを捌けるサーバーに並列アクセスしてないのに自分のリクエストだけが原因でサービスダウンが引き起こされることは無いだろうという技術者としての常識を覆しての)推測は通常されるものではありません。ましてや500エラーから図書館業務が妨害されたことを推測してクロールを中止せよというのは無茶苦茶なことを求めています。
ちなみに503エラーであればサーバーが過負荷かメンテナンスです。時間をおかずに次のURLにアクセスしても503の可能性が高いです。サーバーの負荷が高いためウェイトを入れてくれというのは、Retry-AfterというマイナーなHTTPヘッダを使うことで実現できます。ただしRetry-Afterを出力するサービスも考慮するクローラも、ぶっちゃけあまり無いと思います。Google Code Searchで検索したところいくつか実装例が出てきましたが、数少ないです。
http://www.studyinghttp.net/status_code#Code503
逆に問題があるエラーハンドリングは以下のようなものでしょう(サーバーが落ちても良いと思っていると判断されかねないもの)
- エラーが解消されるまで(適切なウェイトや最大試行回数を考慮せずに)リトライする
- 負荷が原因でアクセス制限を受けているということを知った上で、アクセス制限を回避するための工夫をする。
正しい技術的知見の適切な啓蒙について
ソフトウェアのバグ、脆弱性、不具合であれば、それが直ったかどうかが明確に判別が出来るだろうし、時にはそのようなバグは恥ずかしいと非難を浴びせることもあるでしょう(それが技術レベルの向上に繋がることもあります)。しかし「クローラにどの程度の安全機構を組み込むのか」という問題になると、人によって感覚が異なるようです。事故を起こさないためにどの程度の対策をしておけばいいのかというのは、個々の経験則に依る部分が大きいのでしょう。(ここで交通事故に例えるのは不適切です)
私が主張したいのは以下のようなことです(クローラに限った話ではなく一般論として)
- お前らは人が趣味で数時間で作った程度のものに一体どの程度のレベルを要求しているのか、身の程を知れ。
- 実態を知らない初心者(もしくは老害)が「これぐらいのことやって当然だよね」などと平然と口にする、何様のつもりだ。
- 普段はまるで問題にしていないようなことを事故が起きたときに限って「過失があった」といって騒ぎ立てるなクズども。
世の中で稼働しているソフトウェアはバグだらけです、例えばオープンソースプロダクトのChangesを読めばわかるでしょう。仕様やプロトコルを守っているソフトウェアばかりではないし、それでも世の中は動くように出来ているのです。全くお前らは人のミスを責めたてることにばかり夢中で全く生産的ではないばかりか、時に全く問題のないことに対してまで、過失があった、不注意であったと、騒ぎ立てて間違いを広める。そのような行為は啓蒙ではないし、害悪だ。
良いクローラの条件
自分が考える良いクローラの条件は、事故起こさない方法を追求しても限度があるので「何か問題が起きた場合にアクセス拒否する方法が分かりやすい」ことです。アクセス拒否したときに他のユーザーが巻き添えを食わないことなども含みます(動的IPやブラウザに偽装してたりすると面倒)。今回の事件に関して言えば、最初に稼働させたのが固定IPのレンタルサーバーなので、まあ問題ないでしょう。そもそも図書館側がアクセス拒否する方法を知らなかった可能性がある。
という程度のことを警察が判断できるようになると良いですね。
法と技術とクローラと私
こんにちは、趣味や業務で大手ポータルサイトのサービスで稼働しているいくつかのクローラの開発とメンテナンスを行っているmalaです。
さて先日、岡崎市立中央図書館Webサイトをクロールしていた人が逮捕、勾留、実名報道されるという事件がありました。
関連URL: http://librahack.jp/
電話してみた的な話
- http://www.nantoka.com/~kei/diary/?20100622S1
- http://blog.rocaz.net/2010/06/945.html
- http://blog.rocaz.net/2010/07/951.html
この件につきまして法的なことはともかくとして技術者視点での私見を書きたいと思います。法的なことは差し置いて書きますが、それは法的なことを軽んじているわけではなく、法律の制定やら運用やらは、その法律によって影響が出る全ての人々の常識やら慣例やらも含めた実態に即していなければ意味が無いばかりか害悪になると考えるからです。また技術的に解決できる問題については、先ずは技術的な解決を試みるべきであって、特にインターネットの世界では、人間や機械がアクセス先のサービスの利用規約や、アクセス先のサーバーが置いてある国の法律を解釈することが必ずしも期待できないため、性善説もクソもない、機械が読めない法律や利用規約など、そもそも全く配慮されることを期待すべきではない!と考えるべきであり、また人間や機械がそのサービスに固有の利用規約やその国に固有の法律などを理解していたとしても、必ずしもそのルールが尊守されるとは限らないし、ルールが守られることを前提としたシステムの設計は技術的な欠陥が放置されることにつながり、結果として人々の安全やプライバシーを脅かす危険な存在であると言える。つまり、技術者の世界においては、地域や民族に固有のローカルルールや常識や慣例や風習に従わずに、技術的に解決すべきことは技術的に解決すべきであるというのが常識や慣例であり、そういったポリシーを法律家も含めて理解していただく必要があると考えています。
話を戻して、もし意見を聞かせてくれと言われたならば
- クローラには問題ない(刑事責任も民事責任もない)
- サービスの運用に支障をきたしているのであればアクセス拒否して終わり
- 処理能力の向上やバグの修正などの改善を求めるのは図書館と開発ベンダーで相談して勝手にやればいい
- 警察の対応が特別におかしい
と答えるでしょう。
もし自分が同様のクローラを書いたらどうなるか
個人的な感覚では、librahackさんが書いたクローラは当然悪意があるものだとは思わないし「特別に行儀が悪い」とも思わない。自分が同じ目的のプログラムを書いたならば、おそらく大差ない内容になるでしょう。
具体的には
- robots.txtを無視します
- metaタグを無視します
- ウェイトを入れません(入れるとしてもごく短い)
- 一部500エラーが出てもクロールの中止やプログラムの見直し等は行わない
- むしろ適切なウェイトと最大試行回数を設定した上でリトライすることを検討する
- 一度取得したページについてはキャッシュしてしばらくアクセスしないような制限を加えるが、開発中ならその限りではない
- 開発中、あるいは自分専用サービスとして作っている限りは、UserAgentを変えない(使用しているライブラリのデフォルト)
もちろん事前にアクセス先のサービスに対して何らかの知識があるなら、多少加味するだろうが、同様の事例であれば逮捕される可能性が高い。俺じゃなくてよかった。
なぜrobots.txtやmetaタグを無視しても良いと考えるのか
robots.txtやmetaタグによるbotの拒否は、ロボット型の検索エンジンのクローラが際限なく動的に生成されるリンクを辿っていって双方のサーバーリソースに過大な負荷をかけたり、公開されるべきでないコンテンツが検索エンジン経由で公開されたりといった事故を防ぐのが目的(という認識)なので、特定サービス向けに特定パターン以外のリンク先を探索しない個人的な使用目的の巡回ツールに対してまで、robots.txtやmetaタグの規定するルールを適用するのは適切ではないと考えているからです。
なぜウェイトを入れる必要がないと考えるのか
リクエストを並列して投げない(前回のリクエストの完了を待ってから次のリクエストを発行するようになっている)ならば、相手先のサーバーに対して与える負荷は限定的であり、一般ユーザーが通常の利用目的でブラウザを使ってかける負荷の上限と大差がないと考えるからです。更新チェックなどの目的で同一の(更新されている確率が低い)URLに対してウェイトを入れずに数秒、数分の間隔で自動アクセスするのは、非常識であると考えます。しかし、同じURLに対する重複したアクセスがなく、同一ドメインのリンク先をn段階辿ってまとめて保存するような機能は、本来ブラウザに備わっていてもおかしくないようなもので、自前で書いたツールを使っているだけで通常のブラウジング行為の延長線上であると捉えるべきです。古いIEには実際そういう機能がありました(ウェイト入れてたかどうかとかは調べてない)。
なぜ500エラーが出てもクロールを中止する必要がないと考えるのか
自分のリクエストが原因でエラーが出ているのか区別がつかないので、単に時間をおいて再試行すれば良いと考えるからです。全てのレスポンスがエラーを返すようになったならば、その段階で目的が達成できないのでプログラムの見直しを行うことになるでしょう。500レスポンスは単にそのリクエストに対してエラーが出ているというだけなので、自分のリクエストに原因があるとは考えません。なのでこの場合の適切なエラーハンドリングはクロールの停止やプログラム開発の停止ではありません(適切なウェイトを入れた上で再試行します)。もし403エラーが返ってきているのであれば、自分のリクエストが何らかの理由で拒否されているだろうから、処理内容を見直す必要があると考えます。403レスポンスが返ってきたら、別のUAや別の回線からのアクセスを試して、何らかの自動的な制限に引っかかったのか、あるいは自分の書いたプログラムが決め打ちでアクセス拒否されているかどうかを判断したうえで、サービス運営者に問い合わせるなどするでしょう(アクセス拒否されないためにはどうすればいいか聞く)。気軽に問い合わせできる感じでなかったら開発を中止する。
botがサービス運営に支障を来す場合にサービス運営者の取るべき行動について
- 使用しているhttpdのマニュアルとにらめっこして該当のbotに対して403を返すようにしましょう
- もし過剰なアクセスにより金銭的な負担が発生しているのであれば402 payment requiredを返すのも良いでしょう。youtubeが使っています。
- 手動でルールを追加するのが面倒であればIPアドレス毎の帯域制限やアクセス回数の制限を行ないましょう。大抵のhttpdで適切なモジュールがあるはずです。
- 403を返すだけの処理だけでもサーバーのリソースを大量に消費してサービス運営に支障が出るレベルのアクセス回数であるのなら、iptablesで拒否するなどしましょう。
- アクセス拒否されていることを検知して自動的に複数のIPアドレスからのアクセスを行って来たり、UserAgentを偽装してアクセス拒否することを困難にしていたり、帯域の消費だけでサービス運営に支障をきたすようなレベルであれば攻撃とみなしましょう。警察の出番だ。
行儀の良いbotの話
- ウェイトを入れるのは良い慣習だ。
- エラーが返ってきたらクロール頻度を調整するのは良い慣習だ。
- botの目的や連絡先が分かるようにするのは良い慣習だ。
botの世界には実効性があるのかどうか不明な慣習があります。これらを守ってなくても大した問題ではないと考えています。
- Fromヘッダにメールアドレスを入れる → アクセスログに残らない、自称しているだけで確実にそのメールアドレスの持ち主とは限らない
- 過負荷時のRetry-Afterヘッダ → 守ってくれなければ意味が無い、行儀の悪いbotはそもそも守らない、処理能力改善することを考えたほうがマシ
これらはあくまで良い慣習であって、守っていないからと言って悪意があるものだとは言えない。ライブラリの機能を叩いて3分で作れるような書き捨てのスクリプトでいちいちそのようなことが配慮されることを期待すべきではない。攻撃目的で作られたツールというものは、もっと行儀が悪いものであることを知るべきだ。
攻撃目的で作られたツールではなくても問題になることはある。困ったことになる代表例は
- ab(Apache Bench)を管理外のサーバーに対して行う → 普通に落ちたり帯域使い尽くしたりする
- 脆弱性スキャンツールの類 → 脆弱性ある無しに関係なく大量のリクエストを投げるし場合によっては何かデータ書き込んだりする
これでサービスを落とした人の実例を何件か知っている。
まとめ
403返して終わりって事例でポリス沙汰にするな。
Google ToolbarやGoogle Chromeで秘密のURLが漏れるといった話
http://d.hatena.ne.jp/m-bird/20100402/1270190863 とか http://anond.hatelabo.jp/20100403084111 とか
ずいぶん適当なこと書いてあるなと思ったので調べた。
見ているページのURLが送られるかという話
ツールバーは使ってないのでChromeについてだけ軽く検証したので書いておく。検証したバージョンはGoogle Chrome 5.0.366.2 devでモニタに使ったのはFiddler。
見ているページのURLを自動で送信する機能はChrome自体には無い。アドレスバーにURLを貼りつければ検索語句の補完機能が動いて送られることがある。
ただしhttpsの場合はホスト名まで、httpの場合はクエリストリング(URLの?以降)は含まれない。
フォームの自動入力を有効にしたらなんかXMLが送られるけど、これは見てるページのURLは含まれない。フォーム構造のシグネチャを作って送信しているようだ。
http://www.google.com/support/toolbar/bin/answer.py?answer=81841
オートフィル機能はウェブ フォームに自動入力するオプション機能であり、これを有効にした場合は、ウェブ フォームを含むページの構造に関する限定された情報やフォームの配置に関する情報などがツールバーから Google に送信され、Google でそのページのオートフィル機能を改善するために利用されます。ツールバーから送信される情報には、フォームに入力したデータが含まれることがありますが、ツールバーの同期機能を使用してデータをアカウントとともに保存するよう設定している場合を除き、各欄に入力した実際のテキストが Google に送信されることはありません。
フィッシングサイト対策もオフラインで検証していて、見ているページのURLは送らない。 http://www.google.com/support/chrome/bin/answer.py?answer=99020
クラッシュレポートと使用統計データについては調べてない。 http://www.google.com/support/chrome/bin/answer.py?answer=96817
Google ToolbarでもhttpsのURLとクエリストリングはそもそも送られないように配慮されてる。
追記: IE用Google ToolbarのVersion: 6.4.1321.1732について調べた。現在はhttpsのページのホスト名まで送るようになっている。クエリストリングは以前と変わらず送らない。
そんなわけなので、メッセサンオーの話に限って言えば「クエリストリングにパスワードを含むhttpsのURL」はGoogle ToolbarでもGoogle Chromeでも送信されない。
ただし「クエリストリングにパスワードを含むhttpsのURL」に対してリンクが貼られたhttpのURLについては自動送信される可能性があるよ。
もちろん見てるページのURLを信頼出来ない経路で自動で送るような拡張機能もある。
送信されたURLが適切に取り扱われるかという話
「送信された情報が適切に取り扱われているかどうか」については、サーバーサイドの話なんで想像で何を言われても仕方ないとは思うけど、クロールされるかどうかは外部の人間からも検証することが出来る。
第三者から検証できるので「プライバシーに配慮しない方法で未発見のURLを見つけてクロールする」のはリスクが高い。
実際にGoogle ToolbarのPageRank機能を有効にしたうえで秘密のURLにアクセスしてGoogleにインデックスされるかという実験が行われて、それに対するGoogleの中の人のコメントがある。
- http://www.sem-r.com/20/20061211122827.html
- http://blogoscoped.com/archive/2006-12-10-n75.html
- http://www.mattcutts.com/blog/debunking-toolbar-doesnt-lead-to-page-being-indexed/
普通に考えてリスクが高い。俺ならやらない。眠いし寝る。終わり。
追記
http://b.hatena.ne.jp/amatanoyo/20100406#bookmark-20536320
自分で調べろクソが。ツールバーのウェブ履歴機能を指しているならPageRank調べるクエリで送られたURLを残しているので、httpsはホスト名まで、httpはクエリを除くURLになる。検索結果からクリックした場合はクエリ付きのhttpsのURLもウェブ履歴に残る。
翻訳機能をhttpsのページに対して使うと警告が出る http://gyazo.com/6df6b44f1f825e7e58896348f52793ea.png
ウェブページ翻訳はそもそもhttpsのページを翻訳できない http://gyazo.com/74331ff3bf3477e6c446e2b7f2137080.png
サイドウィキはhttpsのページに対しては使用できない http://www.google.com/support/toolbar/bin/answer.py?hl=jp&answer=157471
{kind=link}
{kind=link}
XSSとセキュリティリスクと正しい脆弱性報告のあり方
適当
XSSがある=なんでもやり放題ではない
ブログサービスなど自由にHTMLをかけるようなサービスでは、害が及ばないように表示を丸ごと別のドメインに分けていたり、あるいは別ドメインのIFRAME内で実行したりしているのが普通です。個人情報を預かってるサイトは、重要個人情報についてはHTTPSじゃないと参照できなかったり、そもそも表示しなかったり(パスワードやカード番号等)、決済用のパスワードや暗証番号を入れないと操作できなかったりする。
参考までに
- http://blog.bulknews.net/mt/archives/001274.html (2004年のアメブロ脆弱性の話)
- http://d.hatena.ne.jp/yamaz/20090114 (信頼できないデータを取り扱うドメインを分ける話)
管理用と別ドメインに分けたにも関わらず、script実行できることに対してDISられている例がこちら。
- http://d.hatena.ne.jp/rosylilly/20091216/1260961264
- http://d.hatena.ne.jp/rosylilly/20091219/1261254527
scriptが書ければブラクラを置いて閲覧者に対して嫌がらせすることは出来るし、ブラウザやpluginに脆弱性がある場合「scriptを書けること自体」が深刻な脅威になりうるので、scriptを一切書けないようにするというポリシーも勿論ある。同じ会社が運営しているサービスでもドメインごとにセキュリティポリシーがある。たとえばはてなダイアリだったら、ユーザーの入力したscriptは実行不可、Google AdSenseや一部のブログパーツのスクリプトは実行されて良い、といった具合に決まってる。単にscriptが実行できるというだけで「あのサービスはXSS脆弱性がある、危険だ」と騒ぎ立てるのは良くないことだと思う。
脆弱性があった場合の影響範囲を抑える
- もし初心者がウェブアプリケーションを作るのであれば、まず最初に「脆弱性があっても大丈夫にする」ことを覚えるのが良いと思う。
- さまざまな攻撃手段や、それに対する対策方法を網羅的に学習するのは時間がかかるし、長年運営しているサイトにも放置されている脆弱性があったりする。
- 個人情報を預からないようにするとか、決済機能は外部サイトに頼るとか。
単純な例を言うと「重要な機能にはパスワードの再確認を入れる」ことだ。重要な機能は例えば、パスワードの変更、メールアドレスの変更、サービスの退会などだ。これらの機能にパスワードの再確認が無い場合、XSSが一つあるだけで、アカウントを乗っ取ったり、サービスを退会したり出来てしまう。(パスワード再確認はCSRF対策にもなる)
正しい脆弱性報告のあり方
IPAを通したりすると、対応が遅くなるのが普通です。IPAを通じて脆弱性の報告が来るということは、脆弱性の発見者がセキュリティ専門家だったりするため、対策が取られるまで公開されないことが予測できる。つまりIPAから脆弱性の報告が来る=緊急ではないという図式が成り立ってしまう!!
早急に脆弱性が修正されることを望んでいるのであれば「俺はゼロデイXSSのURLをtwitterに晒したくてウズウズしてるんだよォォォ!!!!」という姿勢を見せながら中の人に連絡するのが良いでしょう。大体その日のうちに何とかしてくれるはずです。
脆弱性の報告はIPA通すと諸々の手続きが面倒くさくなることを知っているため、サービス開発者同士のネットワークでは、IRC、各種IM、Skypeなどで中の人に直接知らせるのが普通です。そして脆弱性の報告を受けたら、お礼として焼肉や寿司を奢るという慣習がある。
ところが京都に本社を置くHという会社は、脆弱性報告の謝礼を「はてなポイント」や「カラースター」で代用するという風習があるため、必然的に脆弱性を報告するメリットが少なくなる。これは非常に危険な状態であるため、猛省を促したい。
Google Buzzで意図せず本名公開される箇所がある件
「ちゃんと警告出てただろ、注意すれば防げるんだよ情弱が」派と戦争だよ!!!!!!
実験してみた
- 「非公開の 本名」という名前でGmailアカウントを取る
- 知らない人のGoogleプロフィール(例: http://www.google.com/profiles/bulkneets )を開く
- なんか面白そうだな、フォローしてみよう
別アカウントから見た場合は隠れてるけど

bulkneetsさんから見た場合こうなる。

そんなわけだから本名設定されてるGoogleアカウントでフォローボタンを押すだけで、少なくともbulkneetsさんには非公開の本名が公開されてるけど、なんの警告も出てないですよ。
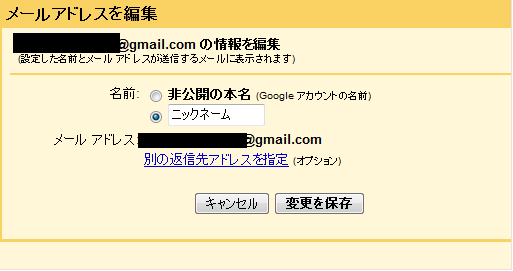
例えばGmailで「本名が表示されないように」メール送信者の名前を変えるのはGmailの設定から出来るけど、
本名バレないようにGmail使ってたのに、Google Buzzの自動フォロー機能やオススメユーザーポチポチしてたら本名バレた!!みたいな人が居そうだなー。Amazonウィッシュリストの時なんかでもそうだけど、明らかにユーザーインターフェースに欠陥があるのに「注意すれば防げる」みたいな無茶なことを言うのは止めましょう。お前らこそが情弱だ!!くたばれ!!!!!!!!!